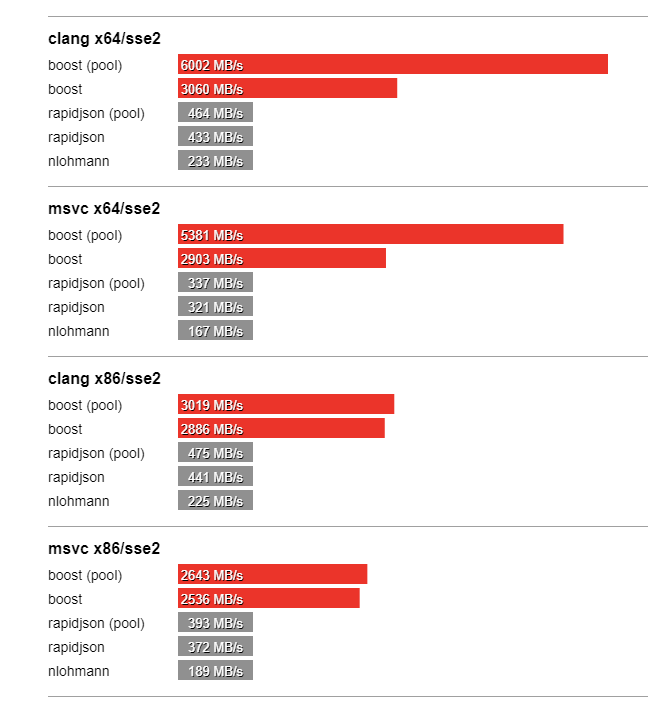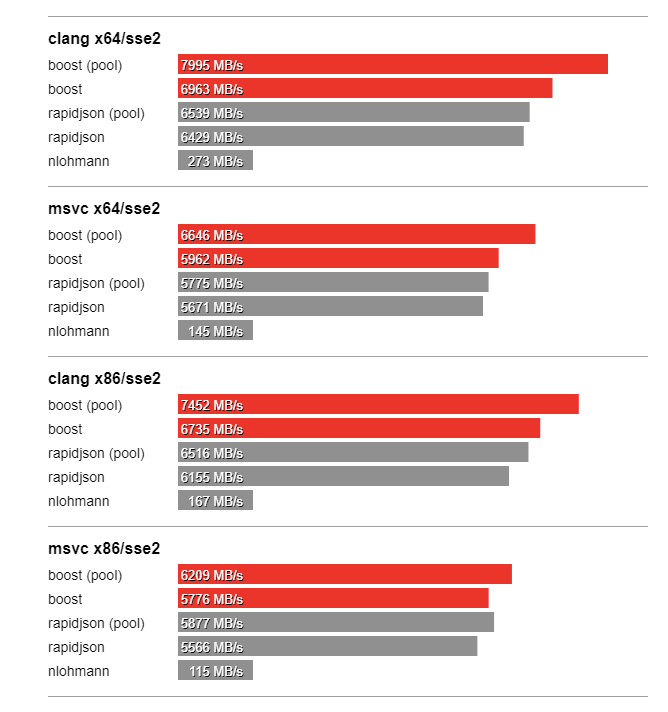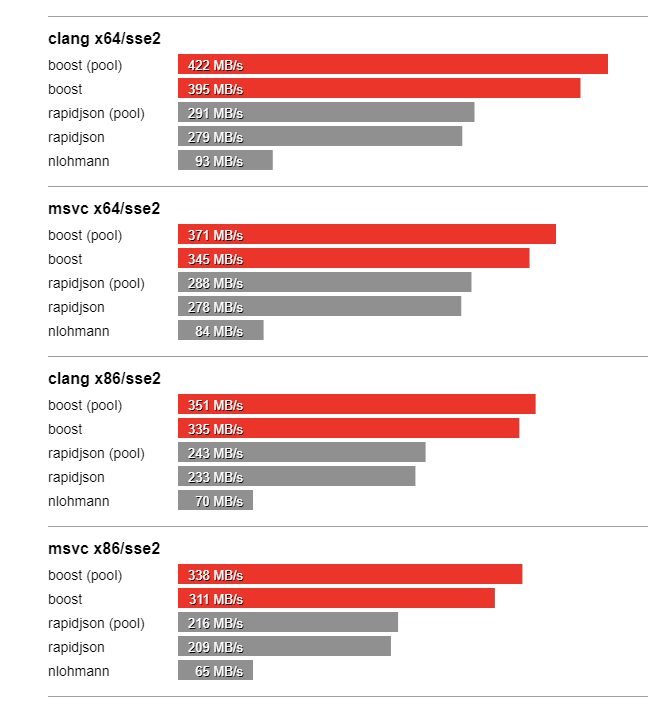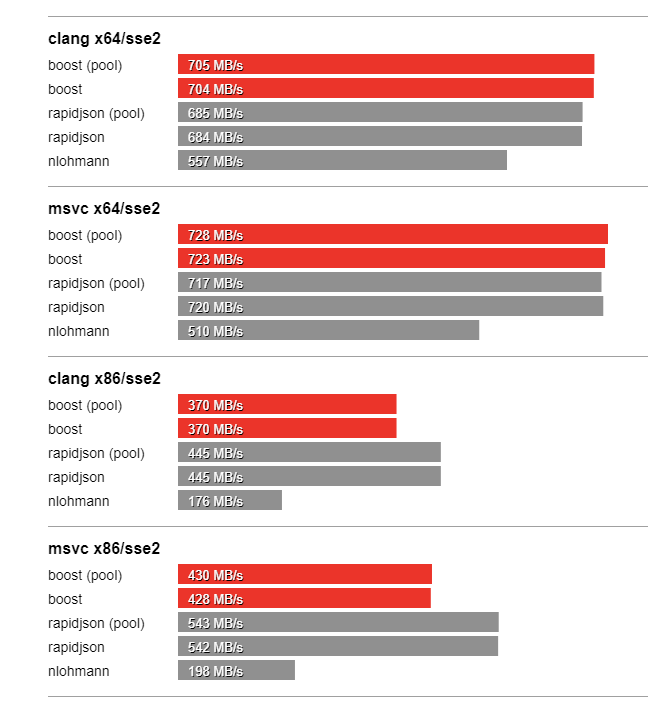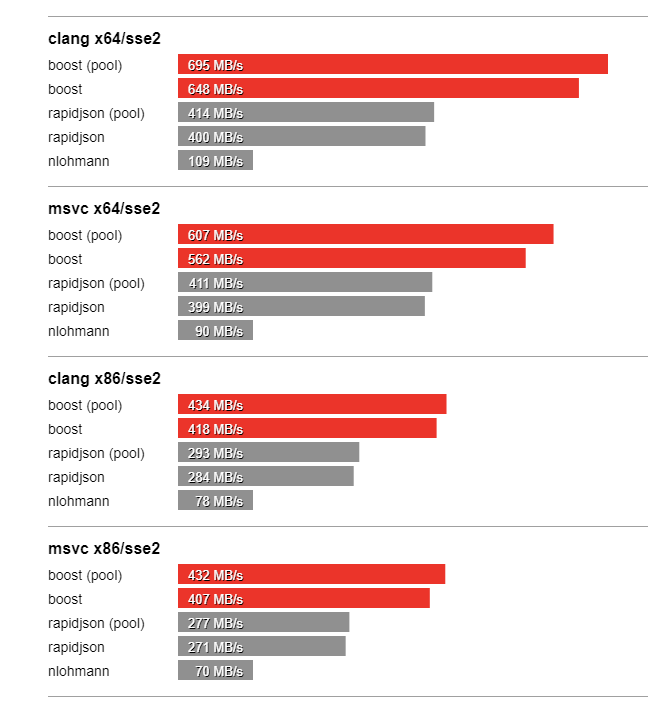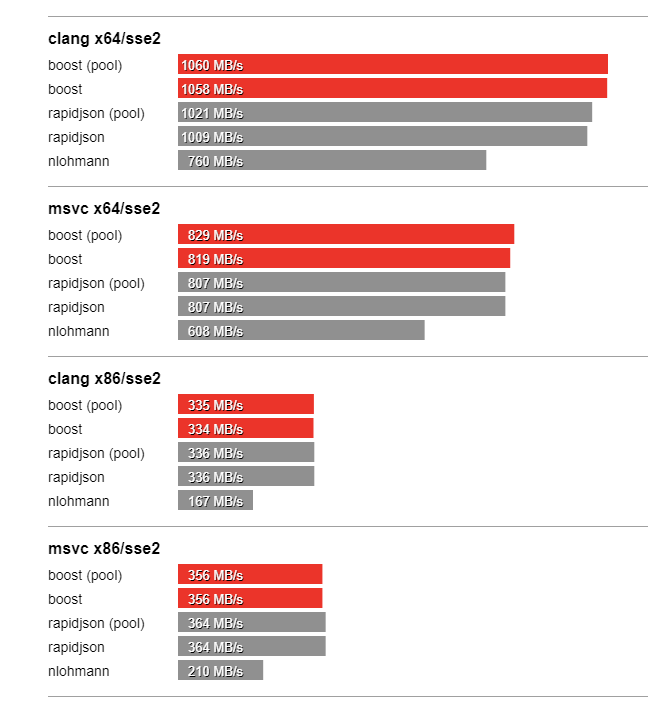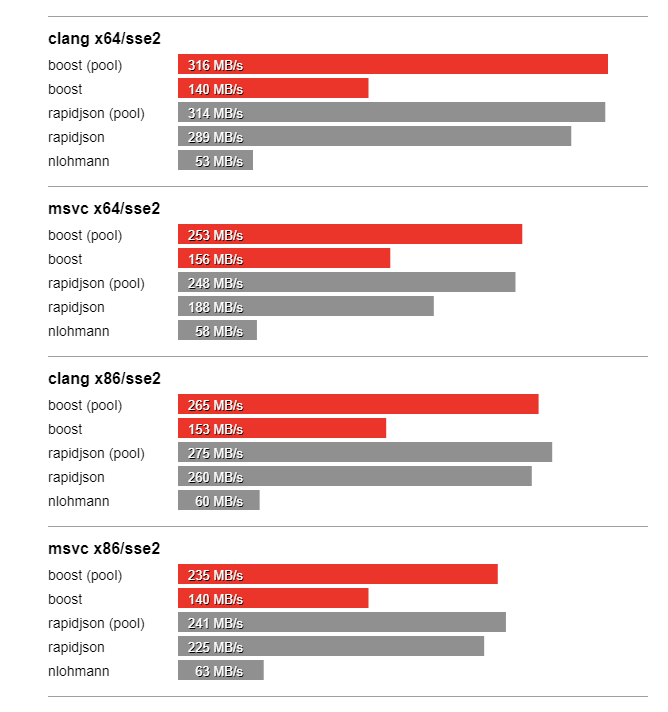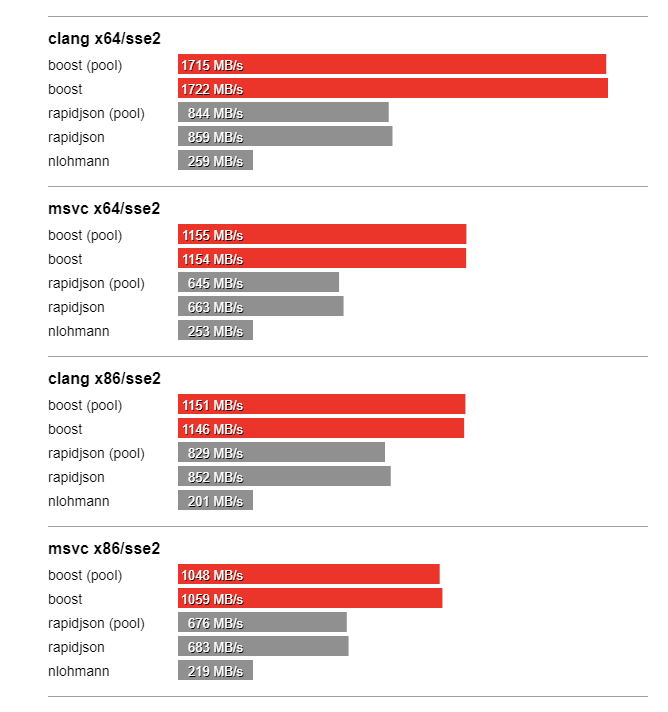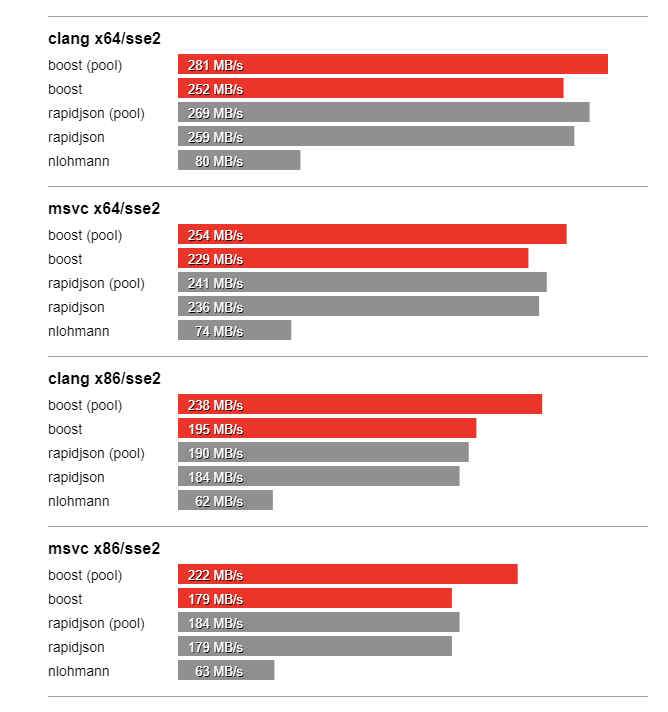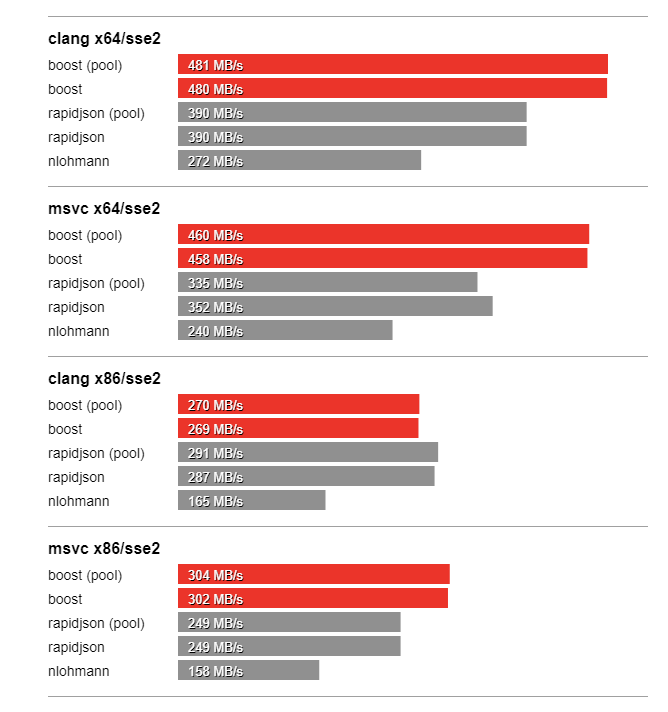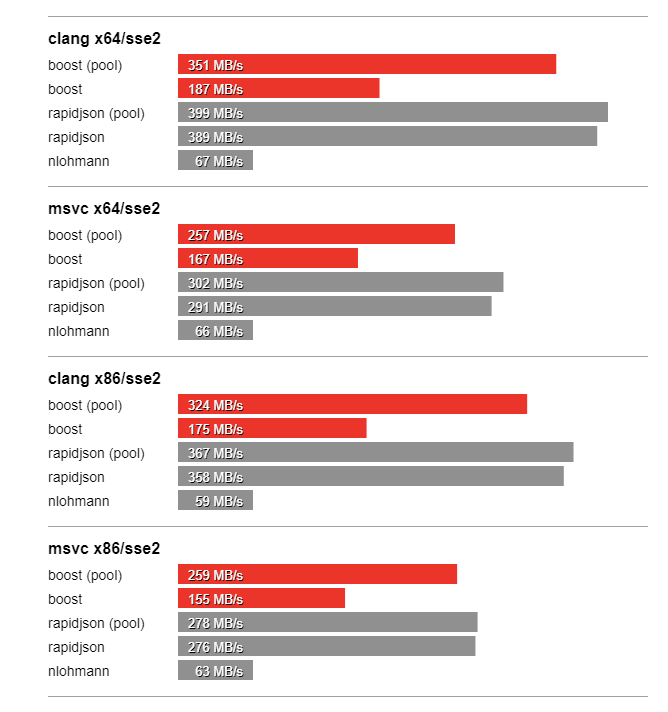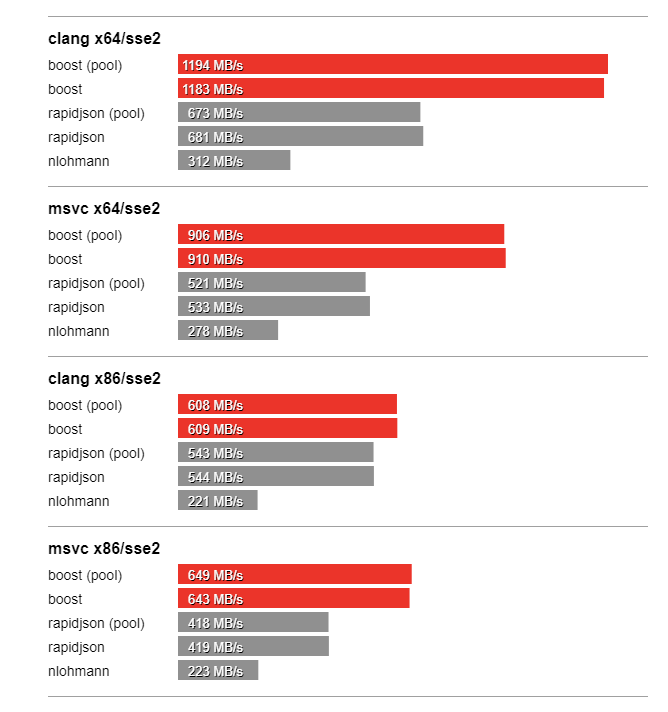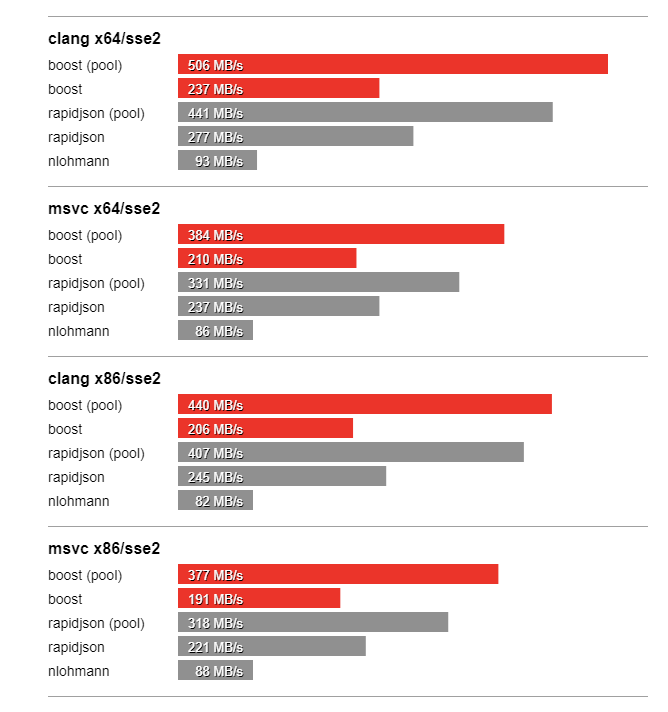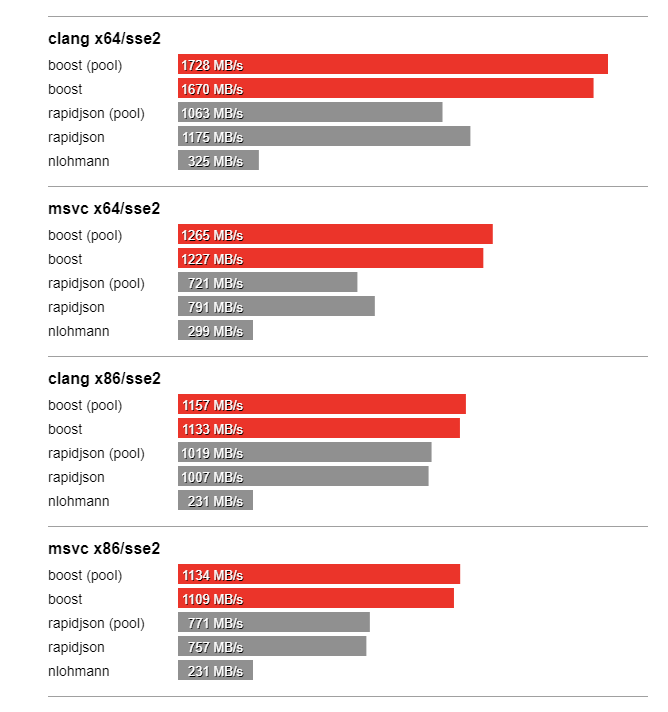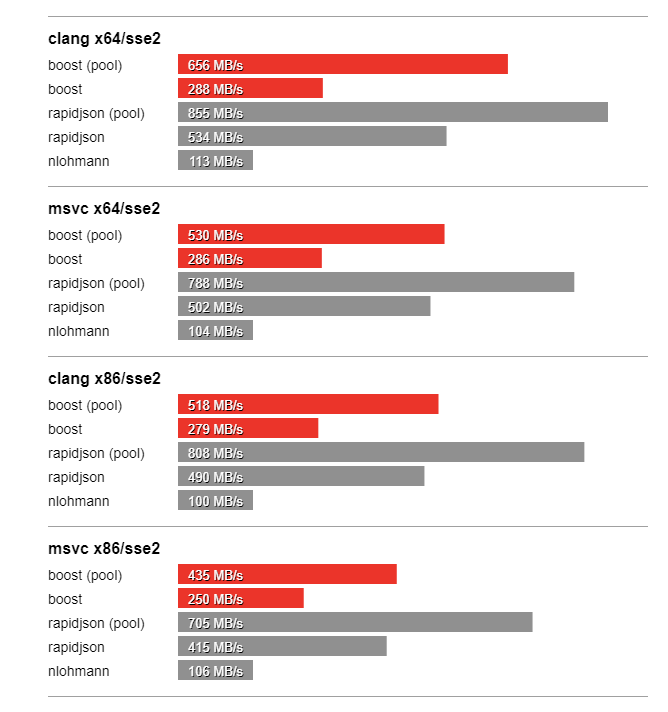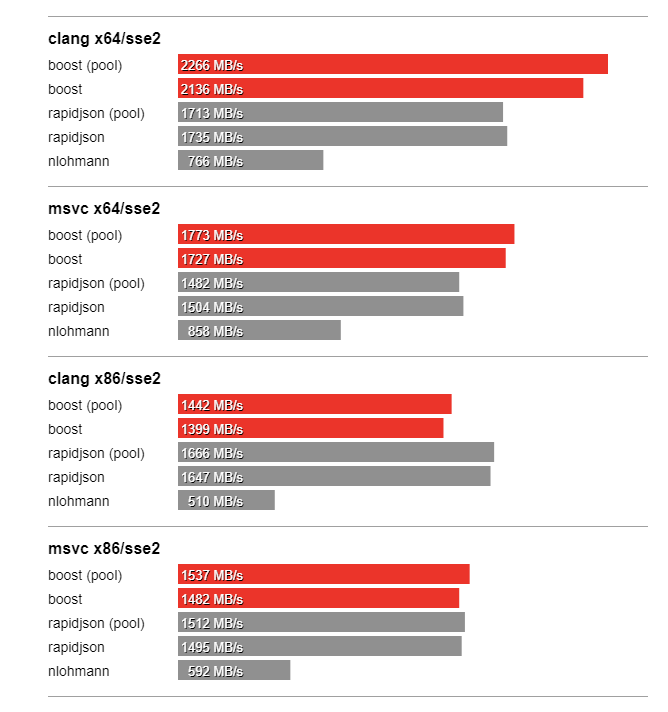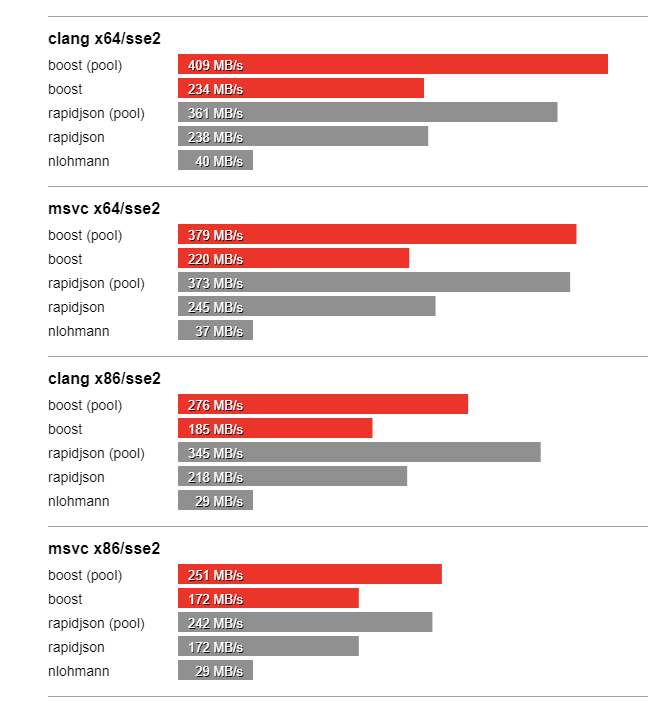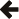


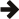
In this section we compare the performance of Boost.JSON against the other two important libraries of interest, RapidJSON which is known for its considerable performance and nlohmann which underperforms but is feature-rich. The bench program measures the throughput of serialization and parsing for the various JSON files located in the data directory. It tests these implementations:
Table 10. Implementations
|
Name |
Description |
|---|---|
|
boost(pool) |
Parses the input using a |
|
boost |
Parses the input using the default memory resource, which uses global
operator |
|
rapidjson(pool) |
Parses the input using an instance of |
|
rapidjson |
Parses the input using an instance of |
|
nlohmann |
Parses the input using the static member function |
The input files are all loaded first. Then each configuration is run for a sufficient number of trials to last at least 5 seconds. The elapsed time, number of invocations (of parse or serialize), and bytes transferred are emitted as a sample along with a calculation of through put expressed in megabytes per second. Several samples (currently six) are generated for each configuration. All but the median three samples are discarded, with the remaining samples averaged to produce a single number which is reported as the benchmark result.
The input files, available in the bench/data directory, are laid out thusly:
Table 11. Input Files
|
Name |
Size |
Description |
|---|---|---|
|
667KB |
A single array with random values and words. |
|
|
2.14MB |
The largest file, containing a huge number of 2-element arrays holding floating-point coordinate pairs. |
|
|
1.69MB |
A large JSON with a variety of nesting, types, and lengths. |
|
|
1,353KB |
One array with random 32-bit integers. |
|
|
596KB |
One array with random 64-bit integers. |
|
|
2,244 bytes |
Holds a randomly generated JSON with assorted types. |
|
|
603 bytes |
Containing a few nested objects with strings. |
|
|
992KB |
Contains a single array with random long strings. |
|
|
631KB |
An export of data from Twitter's API. |
Hardware used for testing: Intel(R) Core(TM) i7-6950X CPU @ 3.00GHz, Windows 10, 64GB RAM.
Thanks to SSE2 optimized string processing algorithms from Peter Dimov, Boost.JSON significantly outperforms all other libraries for parsing and serializing unescaped strings: